
يشهدُ عالَمُنا تحولًا لم تعد فيه “الآلة” مجرد أداة تنفيذ لأوامرك البرمجية الدقيقة، بل شريك يفهم لغتك البشرية العادية، ويتجاوب معك، ويقوم بمهام إبداعية ومعقدة لم نعهدها إلا من البشر. هذا العالم لم يعد خيالاً علمياً؛ إنه الحاضر بفضل القفزة الهائلة في مجال نماذج اللغة الكبيرة (Large Language Models – LLMs).
هذه النماذج ليست مجرد خوارزميات، بل كيانات برمجية قادرة على قراءة كميات ضخمة من النصوص وفهم الأنماط الدقيقة داخل اللغة، لدرجة تمكنها من توليد نصوص جديدة، تلخيص وثائق، كتابة الأكواد، وحتى خوض محادثات تبدو طبيعية بشكل مذهل. ومع كل يوم يمر، تتزايد قدرات هذه النماذج وتصبح أكثر تعقيداً وتطوراً، مقدمة إمكانيات لم يسبق لها مثيل.
بالنسبة لك كـ مبرمج أو مطور، قد يبدو هذا المجال ساحراً لكنه قد يبدو أيضاً بعيد المنال. هل يتطلب الدخول فيه أن تصبح خبيراً في أبحاث التعلم العميق؟ هل تحتاج لتدريب نماذجك الخاصة من الصفر باستخدام حواسيب خارقة؟
الخبر السار هو أن الوصول إلى قوة هذه النماذج أصبح اليوم أسهل من أي وقت مضى، وبوابة هذا الوصول هي ما يعرف بـ واجهات برمجة التطبيقات (APIs). الشركات الرائدة التي تبني هذه النماذج الجبارة تتيح لك، كـ مطور، استدعاء نماذجها واستخدامها في تطبيقاتك بأسطر كود قليلة، دون الغوص في تعقيدات تدريبها أو نشرها.
فما هي نماذج LLM وماذا يمكنها أن تفعل؟ وكيف تستطيع استخدام APIs هذه النماذج لتطوير تطبيقاتك الذكية الأولى؟ ما المفاهيم التي يجب أن تفهمها لتحقيق أقصى استفادة؟ وأين تتجه لتطوير مهاراتك أكثر؟ أكمل قراءة المقال لتجد الإجابات.
جدول المحتويات:
- ما هي نماذج اللغة الكبيرة (LLMs) ولماذا تهتم بها كـ مبرمج؟
- لماذا APIs هي الخيار الأذكى؟
- خطواتك الأولى للبدء مع LLMs عبر APIs (مثال عملي مع OpenAI)
- مفاهيم جوهرية لتحقيق أقصى استفادة: الموجهات (Prompts) والتوكنات (Tokens) والمعلمات (Parameters)
- اعتبارات أساسية للتطبيقات الحقيقية: التكلفة والأداء والأمان
ما هي نماذج اللغة الكبيرة (LLMs) ولماذا تهتم بها كـ مبرمج؟
تُعرف نماذج اللغة الكبيرة (LLMs) بأنها نماذج تعلم آلة ضخمة جداً تم تدريبها على مجموعات بيانات نصية عملاقة تتكون من تريليونات الكلمات والعبارات المأخوذة من الويب، الكتب، والمصادر النصية الأخرى. التحدي الأساسي في تدريب هذه النماذج هو التنبؤ بالكلمة التالية في سلسلة من الكلمات، وعلى نطاق ضخم جداً. هذا التدريب، عبر طبقات متعددة وعلاقات معقدة (غالباً باستخدام بنية “المحولات – Transformers“)، يمنحها فهماً عميقاً لبنية اللغة، قواعدها، وحتى السياق العالمي المرتبط بالكلمات والعبارات.
لا تتعامل LLMs بالكلمات المفردة كوحدة بناء أساسية، بل غالباً ما تستخدم “التوكنات” (Tokens)، وهي قد تكون كلمات كاملة، أجزاء من كلمات، أو حتى علامات ترقيم أو رموز. فهم النموذج للغة يبنى على علاقات هذه التوكنات ببعضها البعض ضمن سلاسل طويلة جداً.
لماذا هذا الفهم العميق للغة يجعلك تهتم كـ مبرمج؟
لأنه يفتح الباب لقدرات كانت في السابق تتطلب قواعد بيانات ضخمة من القواعد اللغوية، أو بناء نماذج مخصصة معقدة جداً لكل مهمة. بعض من أبرز قدرات LLMs التي يمكن استغلالها في التطبيقات تشمل:
- توليد النصوص: كتابة مقالات كاملة، صياغة رسائل البريد الإلكتروني، إنشاء أوصاف للمنتجات، توليد محتوى إبداعي، أو حتى استكمال كود برمجي بناءً على شرح باللغة الطبيعية.
- فهم النصوص واستخلاص المعلومات: الإجابة على الأسئلة حول نص معين، تحديد الكيانات المسماة (أسماء الأشخاص، الأماكن، المنظمات)، استخراج الملخصات، فهم مشاعر الكاتب (تحليل المشاعر – Sentiment Analysis).
- تحويل وتنسيق النصوص: إعادة صياغة الفقرات بأساليب مختلفة، تصحيح الأخطاء الإملائية والنحوية، تحويل النص إلى صيغ منظمة مثل JSON أو قوائم.
- البرمجة وشرح الأكواد: شرح كيف يعمل جزء من الكود، اقتراح إصلاح للأخطاء (Debugging)، أو حتى توليد أجزاء من الكود بناءً على وصف باللغة البشرية.
- المحادثة التفاعلية: بناء روبوتات محادثة (Chatbots) قادرة على فهم السياق والإجابة بشكل طبيعي في محادثة متسلسلة.
فكر في أي مكان في تطبيقاتك تتعامل فيه مع بيانات نصية قادمة من المستخدمين أو من مصادر أخرى. يمكن لقدرات LLMs أن تضيف طبقة جديدة تماماً من الذكاء والمعالجة لتلك البيانات. يمكنها تحليل آراء العملاء تلقائياً من التعليقات، مساعدة المستخدمين في صياغة محتواهم، إنشاء محتوى تسويقي بشكل آلي، أو حتى بناء نظام دعم فني يعتمد على محادثات طبيعية.
إمكانات التطبيقات لا حصر لها، وبدلاً من قضاء شهور أو سنوات في بناء هذه القدرات بنفسك، يمكنك الوصول إليها جاهزة للاستخدام… كيف؟ عبر APIs.
لماذا APIs هي الخيار الأذكى للمبرمج؟
إذا كانت LLMs هي الكنز الرقمي، فإن الـ APIs هي المفتاح الذهبي الذي يتيح لك الوصول إليه ببراعة وسرعة. دعنا نتناول لماذا استخدام واجهات برمجة التطبيقات السحابية لنماذج LLM هو المسار الأكثر عملية للمطورين اليوم، خاصة عند البدء.
تصور البدائل:
تدريب نموذجك الخاص من الصفر: مهمة شبه مستحيلة للأفراد والشركات الصغيرة والمتوسطة. تتطلب فرق بحثية متخصصة في الذكاء الاصطناعي، كميات هائلة من البيانات عالية الجودة والكمية، وقوة حوسبة لا تُصدق (عشرات الآلاف من معالجات الرسوميات GPU المتطورة تعمل لأسابيع أو أشهر) بتكلفة تقدر بملايين أو حتى مليارات الدولارات. ناهيك عن تحديات هندسة البرمجيات والنشر.
استخدام نماذج مفتوحة المصدر ونشرها بنفسك: هناك نماذج مفتوحة المصدر ممتازة (مثل Llama، Mistral)، ولكن حتى استخدامها يتطلب بنية تحتية حاسوبية قوية نسبياً لنشر النموذج وتشغيله واستيعاب عدد طلبات المستخدمين. كما أنك ستحتاج لخبرة في التعامل مع الأجهزة، البرمجيات السحابية، وتحسين الأداء، بالإضافة إلى متطلبات تحديث النماذج وصيانتها.
الآن قارن ذلك بالآتي:
استخدام APIs التي توفرها شركات رائدة (مثل OpenAI، Anthropic، Google):
- وصول فوري للقوة: أنت تستفيد مباشرة من أحدث وأقوى النماذج التي استثمرت الشركات العملاقة سنوات وملايين الدولارات في تدريبها وتحسينها. لن تحتاج للقلق بشأن بنية النموذج أو الأجهزة؛ كل ما عليك هو إرسال طلب والحصول على استجابة.
- تجنب التعقيد التقني العميق: ينحصر دورك كمبرمج في صياغة الطلبات المناسبة للنموذج واستخدام الاستجابات في تطبيقك. تتعامل الـ API مع جميع التفاصيل المعقدة خلف الكواليس: تحميل النموذج في الذاكرة، توزيع الحمل على الخوادم، إدارة الأجهزة، وغيرها.
- التوسع التلقائي (Scalability): مهما زاد عدد المستخدمين لتطبيقك، تتولى الشركة المزودة للـ API مهمة التوسع في البنية التحتية تلقائياً. أنت لا تحتاج لإعادة التفكير في كيف تدعم مئات أو آلاف الطلبات المتزامنة.
- التكلفة المرنة والفعالة: يعتمد نموذج الدفع غالباً على الاستخدام الفعلي (Pay-as-you-go)، بناءً على عدد “التوكنات” التي يعالجها النموذج (إدخالاً وإخراجاً). هذا يعني أنك تدفع فقط مقابل الموارد التي تستخدمها، وهو فعال جداً للمشاريع الصغيرة أو المتوسطة. حتى النماذج الأقوى والأغلى توفر طبقة دخول معقولة للتجربة.
- التركيز على القيمة المضافة والابتكار: بدلاً من إنفاق وقت وجهد وموارد هائلة على جوانب التدريب والهندسة الأساسية لنموذج اللغة، يمكنك التركيز كلياً على كيفية تطبيق قدرات LLM لحل مشاكل حقيقية، تجربة أفكار جديدة، وبناء ميزات مبتكرة في تطبيقاتك بشكل سريع جداً.
بشكل أساسي، الـ APIs تقوم بتجريد (Abstraction) تعقيد بناء وتشغيل LLM، تاركة لك الجزء الأكثر متعة وهو كيفية الاستفادة من ذكائها. هذا هو السبب الذي يجعل استخدام APIs هو البوابة الأكثر واقعية وقوة لك كـ مبرمج لدخول عالم نماذج اللغة الكبيرة وتطوير تطبيقاتك الذكية الأولى.
خطواتك الأولى للبدء مع LLMs عبر APIs (مثال عملي مع OpenAI)
للخوض في هذا العالم بشكل عملي، سنركز على واحدة من أشهر وأقوى APIs المتاحة حالياً: OpenAI API، التي توفر الوصول إلى نماذج مثل GPT-3.5 و GPT-4. الخطوات العملية بسيطة نسبياً:
الحصول على مفتاح الـ API الخاص بك:
هذا هو الجزء الأكثر حساسية. مفتاح الـ API هو هويتك في نظام المزود (مثل OpenAI)، وبواسطته يتم ربط طلباتك بحسابك واستخداماتك (والتكلفة المترتبة عليها).
- اذهب إلى موقع OpenAI (platform.openai.com).
- قم بإنشاء حساب. ستحتاج لإضافة طريقة دفع (مثل بطاقة ائتمان) حتى للبدء بالرصيد المجاني الذي يقدمونه، للتأكد من هويتك وتحديد سقف للإنفاق المستقبلي.
- بمجرد الدخول للوحة التحكم، ابحث عن قسم “API keys”.
- أنشئ مفتاحاً جديداً. فقط انسخه مباشرة بعد إنشائه! لن يظهر مرة أخرى بعد هذه الشاشة (لأسباب أمنية).
- الأمن أولاً: هذا المفتاح يجب معاملته بسرية قصوى ككلمة مرور لحساب بنكي! لا تضعه مباشرة في كودك المصدري وترفعه إلى Git أو أي مكان عام. أفضل طريقة لتخزينه هي كـ “متغير بيئة” (Environment Variable) على نظام التشغيل الذي تعمل عليه، أو استخدامه عبر ملفات .env التي لا يتم تضمينها في نظام التحكم بالمصادر (Version Control Systems) مثل Git.
إعداد بيئة البرمجة:
سنستخدم بايثون، وهي اللغة الأكثر شيوعاً للتعامل مع LLMs. نحتاج تثبيت مكتبة OpenAI الرسمية ومكتبة لمساعدتنا في قراءة ملفات .env (اختياري لكن موصى به للأمان).
افتح موجه الأوامر (Command Prompt / Terminal) ونفذ الأوامر التالية:

كتابة أول استدعاء لـ API (باستخدام Chat Completions API):
واجهة Chat Completions هي الأكثر حداثة وتنوعاً في استخدام نماذج GPT. بالرغم من اسمها، ليست مخصصة للمحادثات فقط، بل يمكن استخدامها لمعظم المهام (كتابة النصوص، التلخيص، التصنيف، إلخ).
لنكتب كود بسيط لنسأل النموذج سؤالاً:
أولاً، أنشئ ملفاً جديداً في مجلد مشروعك باسم .env وأضف فيه السطر التالي، مع استبدال القيمة بمفتاح الـ API الذي نسخته:
ثانياً، أنشئ ملف بايثون (أو دفتر Jupyter Notebook جديد) وأضف الكود التالي:
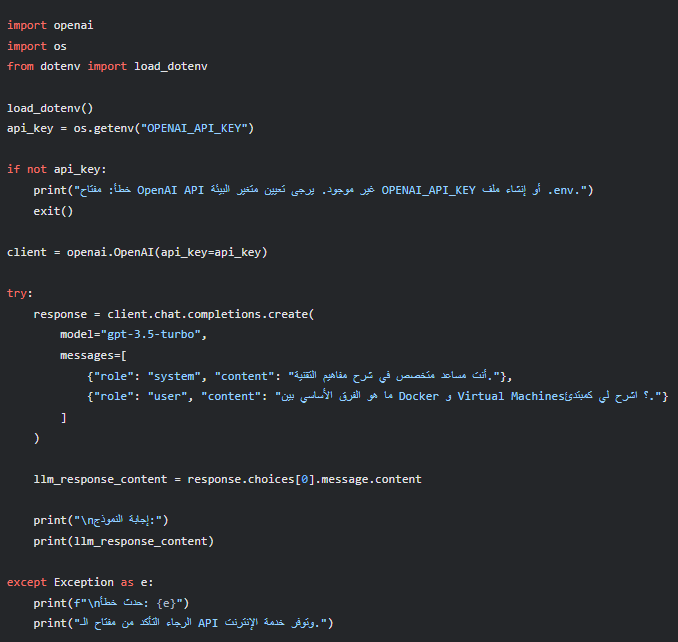
شرح الكود:
- نقوم باستيراد المكتبات الضرورية.
- load_dotenv() تقرأ ملف .env (إذا كان موجوداً) وتحمل محتوياته كمتغيرات بيئة.
- نستخدم os.getenv() لقراءة قيمة مفتاح الـ API من متغيرات البيئة (اسم المتغير التلقائي الذي تبحث عنه مكتبة OpenAI هو OPENAI_API_KEY).
- نقوم بعمل فحص بسيط للتأكد من قراءة المفتاح وإلا سننهي البرنامج لحماية حسابك.
- نُنشئ كائن openai.OpenAI() للاتصال بالـ API. المكتبة تهيئ نفسها تلقائياً إذا وجدت المفتاح في مكانه الصحيح.
- الدالة الأساسية هي client.chat.completions.create():
- model: اسم النموذج (سنبدأ بـ “gpt-3.5-turbo” لأنه متوازن من حيث التكلفة والأداء للمهام العامة).
- messages: قائمة، تمثل حواراً. حتى لو كان طلباً واحداً، فإننا نضع التعليمات أو السؤال هنا. role يحدد المتحدث (نظام System، مستخدم User، مساعد Assistant)، و content هو نص الرسالة. استخدام دور “system” فعال جداً في توجيه سلوك النموذج بشكل عام (“كن مفيداً”، “كن خبيراً في كذا”، “أجب بلغة رسمية”، إلخ).
- نصل إلى الاستجابة من خلال response.choices[0].message.content.
الموجهات (Prompts) والتوكنات (Tokens) والمعلمات (Parameters):
الآن وبعد أن عرفت كيف تتواصل برمجياً مع LLM، هناك ثلاثة مفاهيم أساسية ستحتاجها لتصبح أكثر مهارة في استخدامه، وتتحكم بشكل أفضل في الاستجابات التي تحصل عليها:
1.الموجهات (Prompts) وهندسة الموجهات (Prompt Engineering):
الـ “Prompt” هو النص الذي ترسله للنموذج ليقوم بالعمل المطلوب. ببساطة، هو سؤالك، طلبك، أو التعليمات التي تقدمها له. ولكن ليست كل الموجهات متساوية! “هندسة الموجهات” هي مهارة أو فن (أو علم ناشئ!) صياغة هذه المدخلات بطريقة تضمن أن النموذج يفهم بالضبط ما تريده ويقدم الاستجابة المطلوبة بدقة وشكل محدد.
تذكر أن LLMs تتنبأ بالتوكن التالي بناءً على المدخل والسياق الذي تدربت عليه. Prompt المصمم جيداً يضع النموذج في “السياق” الصحيح ويوجهه نحو مسار التنبؤ الذي تريده.
2.التوكنات (Tokens) ونافذة السياق (Context Window):
كما ذكرنا، النماذج تعمل بالتوكنات. معرفة عدد التوكنات في طلبك واستجابتك المستقبلية ضرورية جداً لسببين رئيسيين:
- التكلفة: تحاسبك معظم شركات الـ API بناءً على إجمالي عدد توكنات الإدخال (في الـ Prompt والـ messages المرسلة) و توكنات الإخراج (في الاستجابة الناتجة). النماذج الأقوى مثل GPT-4 تفرض تكلفة أعلى بكثير لكل توكن مقارنة بـ GPT-3.5. طلب طويل يعني توكنات أكثر وبالتالي تكلفة أعلى. استجابة طويلة أيضاً تعني تكلفة أعلى.
- حدود نافذة السياق (Context Window Limit): كل نموذج لديه حد أقصى لعدد التوكنات التي يمكنه معالجتها في طلب واحد (مدخلات + مخرجات). هذا يسمى نافذة السياق (أحياناً تجد نماذج بقدرة 4K, 8K, 16K, 32K, 128K توكن). إذا تجاوز مجموع توكنات طلبك والتنبؤ المتوقع هذا الحد، ستواجه خطأ API. في حالة المحادثات، حيث ترسل تاريخ الحوار كاملاً في كل طلب، يمكن تجاوز هذا الحد بسرعة مع طول المحادثة.
3.المعلمات (Parameters) :
عند التحدث مع نموذج LLM عبر الـ API، لستَ مجرد مرسل للنصوص. يمكنك أيضاً التحكم في “شخصيته” وكيف يصوغ ردوده باستخدام ما نُسميه المعلمات (Parameters). هذه بمثابة مقبضات تضبط بها سلوك النموذج عند توليد الإجابة.
أهم هذه المعلمات، وكيف تؤثر على استجابته:
- Temperature: هذه المعلمة أشبه بمنظم “الحرارة الإبداعية”. قيمتها تتراوح غالباً بين 0 و 2.
- إذا ضبطت الحرارة قريبة من الصفر (مثل 0.0 إلى 0.5)، تحصل على إجابات مباشرة جداً، متوقعة، وغير إبداعية (مثل الإجابة على أسئلة حقائق مباشرة). كأنك تقول له “أجب تماماً كما تدربت”.
- كلما رفعت الحرارة (0.7 هي القيمة الافتراضية غالباً، ويمكن أن تصل لـ 1.5 أو أكثر)، يصبح النموذج أكثر جرأة وعشوائية وإبداعاً. مفيد لتوليد أفكار جديدة أو محتوى فني، لكن احذر؛ الحرارة العالية قد تؤدي لـ “هلوسات” (اختراع معلومات غير حقيقية)!
- Max Tokens: هو حد أقصى لـ “كمية” النص الذي يمكن للنموذج توليده كرد. يمكنك اعتباره مقياساً لطول الإجابة. تحكم به جيداً لضمان عدم الحصول على نصوص أطول مما تحتاج (تذكّر، التكلفة مرتبطة بالتوكنات!).
- Top P: بديل لـ Temperature في التحكم بالعشوائية، لكن بطريقة مختلفة قليلاً تعتمد على احتمالات الكلمات. كقاعدة عامة، يكفي التركيز على تعديل إما Temperature أو Top P وليس كلاهما معاً.
- N: تريد أكثر من رد واحد لنفس السؤال لتختار الأفضل؟ n تتيح لك ذلك. إذا ضبطتها على 3 مثلاً، ستحصل على 3 إجابات مختلفة للـ Prompt نفسه. لكن كن واعياً جداً: كل استجابة توليدها النموذج تحاسب عليها كـ “مخرج” مستقل، فزيادة n يزيد التكلفة بنفس المقدار تقريباً!
- Stop Sequences (stop): إذا كنت تريد أن يتوقف النموذج عند ظهور كلمة أو عبارة معينة (مثل علامة نهاية جملة مكررة أو كلمة مفتاحية)، يمكنك تحديد ذلك باستخدام stop.
هناك معلمات أخرى مثل frequency_penalty و presence_penalty تؤثر على تكرار الكلمات، ويمكنك استكشافها للتحكم في تنوع اللغة في الاستجابات. بتجربة هذه المعلمات، تتقن توجيه النموذج لتقديم النتائج الأنسب للمتطلبات والأوامر.
اعتبارات أساسية للتطبيقات الحقيقية: التكلفة والأداء والأمان
استخدام LLM APIs في المشاريع الصغيرة للتجربة والتعلم سهل وبتكلفة قليلة (باستخدام الرصيد المجاني). لكن عند الانتقال لتطبيقات قد يستخدمها الكثيرون، أو تتطلب حجماً كبيراً من الطلبات، يصبح التفكير في بعض الجوانب ضرورياً جداً:
- التكلفة:
- قياس الاستخدام: التكلفة مباشرة مرتبطة بعدد التوكنات المرسلة والمستقبلة. استخدم الدوال لتقدير التوكنات وتتبع الاستخدام في لوحة تحكم المزود بانتظام.
- اختيار النموذج المناسب: النماذج الأقل تكلفة (مثل GPT-3.5-turbo) قد تكون كافية للكثير من المهام، وفر بتجنب استخدام النماذج الأعلى تكلفة (مثل GPT-4) إلا عند الضرورة القصوى.
- التحكم في طول الاستجابات: استخدم max_tokens لتجنب استجابات أطول مما تحتاج. لا تتركها قيمة عالية جداً بلا داعي.
- إدارة السياق: في روبوتات المحادثة، لا تحتفظ بسجل كامل للمحادثات اللانهائية إذا كان سيتم إرساله كله في كل طلب. قم بتقليص سجل المحادثة أو لخص الأجزاء القديمة بشكل دوري لتقليل عدد التوكنات المدخلة.
- الدفعات Batch Processing: إذا كان لديك العديد من المهام المتشابهة التي لا تتطلب استجابة فورية، تحقق مما إذا كان المزود يقدم خيارات لمعالجتها على شكل دفعات (batches) بتكلفة أقل.
- الأداء وزمن الاستجابة (Latency):
استدعاء API يعني انتظار رد من خادم بعيد. يمكن أن يستغرق هذا الاستدعاء مئات الميلي ثانية إلى عدة ثوانٍ، اعتماداً على حجم المدخلات والمخرجات وحالة خوادم المزود ونوع النموذج. هذا بطيء جداً مقارنة بالعمليات الحسابية المحلية.- تحسين Prompts: الموجهات المصممة بشكل جيد تحصل غالباً على استجابات أسرع وأكثر دقة من النماذج الأحدث التي تحسنت في فهم التعليمات.
- التشغيل غير المتزامن (Asynchronous Operations): في تطبيقات الويب أو الخدمات الخلفية، لا تجعل البرنامج ينتظر الرد بشكل “معوق” (blocking). استخدم البرمجة غير المتزامنة (Async/Await في بايثون مع مكتبات مثل httpx بدلاً من requests ودمجها مع asyncio أو مكتبات إطار العمل). هذا يسمح لطلبك بالذهاب للشبكة وتعمل تطبيقاتك على أمور أخرى في نفس الوقت بدلاً من الانتظار الخامل.
- اختيار النموذج المناسب: بعض النماذج أسرع في الاستجابة من غيرها (النماذج الصغيرة أو النماذج “المنفصلة” أو “instruct” مقابل نماذج “chat”). تحقق من وثائق المزود.
- إضافة مؤشرات للمستخدم: إذا كان هناك انتظار للرد من LLM، قدم للمستخدم مؤشراً مرئياً بأن النظام يعمل.
- الأمان والخصوصية (Security & Privacy):
- حماية مفتاح الـ API: لا تضعه في الكود المصدر المنشور أو في أي مكان يمكن الوصول إليه علناً. استخدم متغيرات البيئة أو أنظمة إدارة الأسرار. في تطبيقات الواجهة الأمامية (Front-end) في الويب، لا تستدعي API من متصفح المستخدم مباشرة (لأن هذا يكشف مفتاح الـ API!). دائماً اجعل الواجهة الأمامية تستدعي خدمة خلفية خاصة بك (Backend Service)، وتقوم الخدمة الخلفية بالاتصال بـ LLM API باستخدام مفتاح الـ API الخاص بك.
- خصوصية البيانات: عند إرسال بيانات إلى API، أنت تثق بالمزود. راجع سياسات خصوصية البيانات للمزود. بعضهم قد يستخدم البيانات المرسلة لتحسين النماذج (غالباً هذا هو الوضع في النماذج المجانية أو الأرخص ما لم تطلب عكس ذلك وتستخدم خططاً أعلى)، والبعض يلتزم بعدم استخدامها لتدريب النماذج العامة (وهذا أهم إذا كنت تتعامل مع بيانات المستخدمين). إذا كنت تتعامل مع بيانات شديدة الحساسية أو سرية، قد تحتاج لاستخدام نماذج لا تجمع البيانات أو تستضافة النماذج بنفسك (وهو أصعب).
- حقن الموجهات (Prompt Injection): قد يحاول المستخدمون أو الجهات الخبيثة إدخال تعليمات “خبيثة” ضمن الـ Prompt الخاص بهم بهدف تغيير سلوك النموذج أو جعله يتجاهل تعليمات النظام أو يكشف عن بيانات غير مصرح بها. هذه مشكلة معقدة، ويمكن تخفيفها بتصميم Prompts قوية جداً، وتقييم مخرجات النموذج قبل استخدامها، وقد توفر بعض APIs حماية مدمجة ضد بعض أشكال الهجمات هذه.
- ضبط جودة المخرجات (Output Quality) والمعالجة اللاحقة (Post-processing):
LLMs ليست مضمونة دائماً لتقديم إجابات صحيحة أو بالشكل المطلوب تماماً. قد “تهلوس” (تخترع معلومات)، تقدم معلومات متحيزة من بيانات تدريبها، أو تخالف التنسيق المطلوب.- تحسين Prompt: مرة أخرى، الهندسة الجيدة للموجهات هي خط الدفاع الأول.
- التحقق والفلترة: في التطبيقات الحساسة، لا تستخدم استجابة النموذج مباشرة دون تحقق. إذا كان تطبيقك يولد إجابة واقعية لسؤال طبي مثلاً، يجب أن يتم تدقيق هذه الإجابة من قبل مصدر موثوق قبل تقديمها للمستخدم. قد تحتاج لبناء طبقة إضافية من الكود لفحص الاستجابات بحثاً عن أخطاء أو محتوى غير لائق قبل عرضه (Post-processing/Moderation). بعض الـ APIs (مثل OpenAI) توفر أيضاً نماذج Moderation يمكن استدعاؤها لفحص النص المنتج والتأكد من خلوه من محتوى ضار قبل نشره.
هذه الاعتبارات قد تبدو كثيرة، ولكنها جزء من بناء تطبيقات قوية وموثوقة. فهمها مسبقاً يجعلك مستعداً لمواجهة التحديات أثناء توسيع نطاق استخدامك لـ LLM APIs.
الخاتمة:
لقد استكشفنا معاً كيف أن نماذج اللغة الكبيرة هي قوة ضخمة غيرت المشهد الرقمي، وكيف تجعل الـ APIs الوصول لهذه القوة متاحاً ومباشراً بين يديك كـ مبرمج. لم تعد القدرة على بناء تطبيقات تفهم اللغة وتتفاعل معها بذكاء خارق حلماً بعيد المنال، بل واقعاً بفضل هذه الأدوات التي كسرت حاجز التعقيد.
تذكر، ما قرأته هنا هو المفتاح لتبدأ، لكن الإتقان الحقيقي يأتي بالممارسة والتطبيق. استخدم الكود والأمثلة كنقطة انطلاق. تجرأ على تعديل الموجهات، جرّب المعلمات المختلفة، واستفد من الفضول لبناء مشاريعك الذكية الخاصة، مهما كانت بسيطة في البداية. عالم الـ APIs لـ LLMs يتطور بسرعة، والأدوات المتاحة لك تزداد قوة يوماً بعد يوم.

